ESP32 2432S028R (CYD)でLVGL - ダブルバッファとマルチコアで応答性を高める(2)
前回は…
LVGL の全体概要における「レンダリングエンジン」と「パネルへの出力」、および介在する「画像メモリ」との関係性を紐解いてきました。
また Arduino 用 LVGL のスケッチ例 LVGL_Arduino で、「画像メモリ」のサイズを決めている「分割数=マジックナンバー 10」について考察と実験を行い、GUI の応答性を「最適化」するための検討を行いました。
画像メモリのサイズと分割数に関する検討結果
/*LVGL draw into this buffer, 1/10 screen size usually works well. The size is in bytes*/
#define DRAW_BUF_SIZE (TFT_HOR_RES * TFT_VER_RES / 10 * (LV_COLOR_DEPTH / 8))- マジックナンバー
10は、1フレームにおけるレンダリング領域の分割数を表す - 分割数は、ハードウェアで並列化できるレンダリング領域の個数を想定している
- 分割数が小さくなるとオーバーヘッドは小さくなるが、画像メモリが大きくなる
- ∴ アプリ全体でメモリ容量の許す限り分割数を小さくすれば応答性を上げられる
今回はこれに加え、以下を追加すべく検証を行いたいと思います。
- ダブルバッファ化とマルチコア/マルチタスク化でスループットを上げられる
ダブルバッファとマルチコアによる並列化
LVGL には lv_display_set_flush_wait_cb() という関数があり、その説明はこうです。
However with the help of
lv_display_set_flush_wait_cb()a custom wait callback be set for flushing. This callback can use a semaphore, mutex, or anything else to optimize waiting for the flush to be completed. The callback need not calllv_display_flush_ready()since the caller takes care of that (clearing the display’s flushing flag) when your callback returns.
lv_display_set_flush_wait_cb()を使用すると、フラッシュ用のカスタム待機コールバックを設定できます。 このコールバックは、セマフォ、ミューテックス、またはその他の手段を使用して、フラッシュが完了するまでの 待機を最適化できます。コールバックが返されたときに呼び出し元がその処理 (ディスプレイのフラッシュ フラグのクリア) を行うため、コールバックはlv_display_flush_ready()を呼び出す必要はありません。 (訳:Google 翻訳)
う〜ん、実装イメージが湧きにくい説明ですが、「フラッシュ用のカスタム待機コールバック」を待機する wait_for_flushing() の次のような処理を見ると謎が解けます。
if(disp->flush_wait_cb) { // 「フラッシュ用のカスタム待機コールバック」が設定されている場合、
if(disp->flushing) { // ディスプレイパネルに転送すべき画像データがあれば、
disp->flush_wait_cb(disp); // 画像データの転送が完了するまで待機する(=ブロックされる)
disp->flushing = 0; // lv_display_flush_ready() の代わりに転送完了をマークする
}
}
else { // 「フラッシュ用のカスタム待機コールバック」が未設定の場合は、
while(disp->flushing); // lv_display_flush_ready() による転送完了の通知をポーリングする
}ポイントは上記コード3行目の disp->flush_wait_cb(disp); で、セマフォのリリースを待つようにコールバック関数を実装すれば、コンテキストスイッチ によるレンダリングタスクの切り替えが可能になります。この仕組みを図にすると次の様になるハズです。
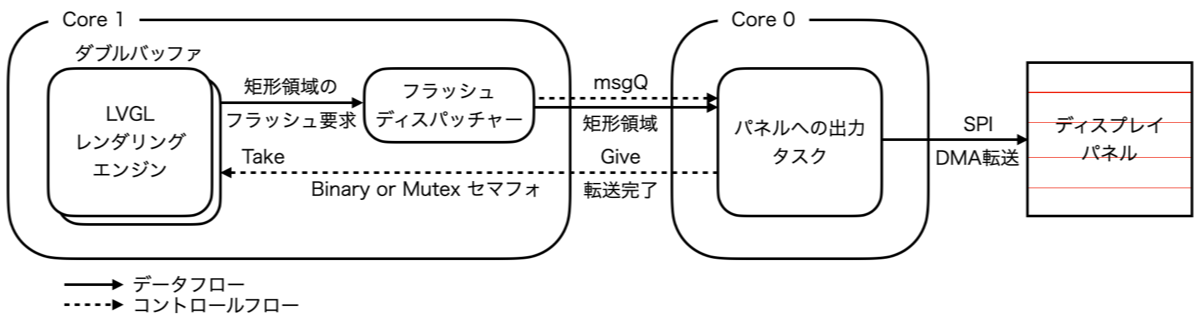
とは言え、並列化の実装を議論している [Parallel rendering] General discussion #4016 を読んでみても、LVGL のレンダリングがマルチタスク化されているかまでは分かりませんでした。が、少なくともパネルへの出力をコア0に移し、ダブルバッファ化することでスループットは上がるハズです!
プログラムの作成と実行
前回作成したベースライン LVGL_Arduino_LovyanGFX を元に、LVGL_Arduino_MultiCore を作成します。
LVGL_Arduino_FastRendering
├── LVGL_Arduino_LovyanGFX
│ └── LVGL_Arduino_LovyanGFX.ino
└── LVGL_Arduino_MultiCore
└── LVGL_Arduino_MultiCore.inoベースラインの改修
分割数とバッファ数の設定
DRAW_BUF_N_BUFS を 1 にすれば、シングル版との比較テストができるようにしました。また残念ながら分割数2では、容量オーバーでダブルバッファ分のメモリが確保できませんでした。
#define DRAW_BUF_N_BUFS 2 // バッファ数(1 or 2)
#define DRAW_BUF_N_DIVS 3 // 分割数(2 〜 10)画像メモリの定義
従来のマジックナンバー 10 を DRAW_BUF_N_DIVS で置き換え、また画像メモリへのポインタはダブルバッファ分の配列に変更してます。
/*LVGL draw into this buffer, 1/10 screen size usually works well. The size is in bytes*/
#define DRAW_BUF_SIZE (TFT_HOR_RES * TFT_VER_RES / DRAW_BUF_N_DIVS * (LV_COLOR_DEPTH / 8))
static uint8_t* draw_buf[2] = { NULL, };パネルへの出力用タスクの設定
以下の関数を追加します。
flush_init()
「更新すべき矩形領域」用のメッセージキューと「更新完了を通知」するセマフォを生成し、コア0に「パネルへの出力」を行うflush_task()を追加します。flush_task()
メッセージキューから「更新すべき矩形領域」を取り出し、「パネルへの出力」を完了したらセマフォをリリースします。flush_wait()
lv_display_set_flush_wait_cb()で設定されるべきコールバック関数で、呼び出し元をブロックするためにセマフォがリリースされるまで待つだけの関数です。
マルチコア/マルチタスクの設定
//----------------------------------------------------------------------
// パネルへの出力用タスクの設定
//----------------------------------------------------------------------
#define FLUSH_TASK_STACK_SZ 2048 // スタックサイズ
#define FLUSH_TASK_PRIORITY 1 // 優先順位
#define FLUSH_TASK_CORE 0 // コア0
// メッセージキューの内容
typedef struct {
int32_t x, y, w, h; // 更新領域
uint8_t *buf; // 画像メモリへのアドレス(ダブルバッファのどちらか一方が指定される)
} MessageQueue_t;
// コア0〜1間のハンドシェイク用セマフォとメッセージキュー
static TaskHandle_t taskHandle;
static QueueHandle_t queHandle;
static SemaphoreHandle_t semHandle;
// LVGL が指定した画像メモリ中の更新領域を LCD パネルに DMA 転送する関数の本体
inline void flush_draw_buf(uint16_t x, uint16_t y, uint16_t w, uint16_t h, uint8_t *buf) {
tft.setAddrWindow(x, y, w, h);
tft.pushPixelsDMA((lgfx::rgb565_t *)buf, w * h); // { startWrite(); writePixelsDMA(data, len); endWrite(); }
}
// パネルへの出力用タスク
static void flush_task(void *pvParameters) {
MessageQueue_t queue;
while (1) {
// 画像メモリの準備完了を待つ
if (xQueueReceive(queHandle, &queue, portMAX_DELAY) != pdTRUE) {
Serial.println("unable to receive queue.");
continue;
}
// LCD パネルへの転送を実行する
flush_draw_buf(queue.x, queue.y, queue.w, queue.h, queue.buf);
// 転送終了を通知する
if (xSemaphoreGive(semHandle) != pdTRUE) {
Serial.println("unable to give semaphore.");
}
}
}
// 画像データの転送が完了するまで待機する(=ブロックされる)関数
static void flush_wait(lv_display_t *disp) {
// 転送終了が通知されるまで待機する
if (xSemaphoreTake(semHandle, portMAX_DELAY) != pdTRUE) {
Serial.println("unable to take semaphore.");
}
}
// パネルへの出力用タスクを初期化する
static bool flush_init(void) {
// セマフォ、メッセージキューを初期化する
semHandle = xSemaphoreCreateBinary();
queHandle = xQueueCreate(1, sizeof(MessageQueue_t));
if (queHandle == NULL || semHandle == NULL) {
Serial.println("unable to create queue or semaphore.");
return false;
}
// コア0に転送タスクを生成し、即座に起動する
bool ret = xTaskCreatePinnedToCore(
flush_task, "flush_task",
FLUSH_TASK_STACK_SZ, // The stack size
NULL, // Pass reference to a variable describing the task number
FLUSH_TASK_PRIORITY, // priority
&taskHandle, // Pass reference to task handle
FLUSH_TASK_CORE
);
return (ret == pdPASS);
}フラッシュディスパッチャの定義
元は「パネルへの出力」を担当していた my_disp_flush() を flush_task() のディスパッチ担当に役割変更します。
my_disp_flush()
// パネルへの出力用ディスパッチャ
static void my_disp_flush(lv_display_t *disp, const lv_area_t *area, uint8_t *px_map) {
// 画像メモリのアドレス(ダブルバッファの一方)と更新すべき領域をメッセージキューに設定する
MessageQueue_t queue = {
.x = area->x1,
.y = area->y1,
.w = lv_area_get_width(area),
.h = lv_area_get_height(area),
.buf = px_map
};
// メッセージを送信する
if (xQueueSend(queHandle, &queue, portMAX_DELAY) != pdTRUE) {
Serial.println("unable to send queue.");
}
}コア0の初期化とダブルバッファの設定
初期化関数 flush_init() を呼び出し、画像メモリ用のダブルバッファを設定するコードを setup() に追加します。
setup()
void setup() {
...
// パネルへの出力用タスクを生成する
if (!flush_init()) {
Serial.println("unable to initialize flush task.");
while (1) delay(1000);
}
...
// パネルへの出力用ディスパッチャと転送完了を待つ関数を登録する
lv_display_set_flush_cb(disp, my_disp_flush);
lv_display_set_flush_wait_cb(disp, flush_wait);
// ダブルバッファ用画像メモリを確保する
for (int i = 0; i < DRAW_BUF_N_BUFS; i++) {
draw_buf[i] = (uint8_t*)heap_caps_malloc(DRAW_BUF_SIZE, MALLOC_CAP_DMA | MALLOC_CAP_INTERNAL);
}
// 確保した画像メモリを LVGL に登録する
lv_display_set_buffers(disp, draw_buf[0], draw_buf[1], DRAW_BUF_SIZE, LV_DISPLAY_RENDER_MODE_PARTIAL);
...
}実行結果
現在 esp32 by Espressif v3.2.0 (ESP-IDF v5.4.1) で ランタイムエラーが発生しています。LovyanGFX の issue に上げていますが、コンパイルは v3.1.3 まででお試しください。 » 1.2.7 で解消されました。
lv_demo_music() を 前回のシングルバッファ版 と比べてみました。
- シングルバッファ版(括弧内は画像メモリのサイズおよび1フレーム分の平均転送時間)
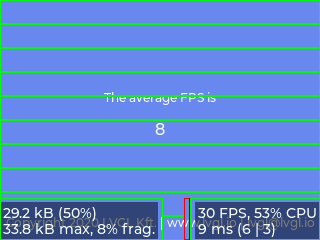
10分割 (15KB), 8FPS (17.4ms) 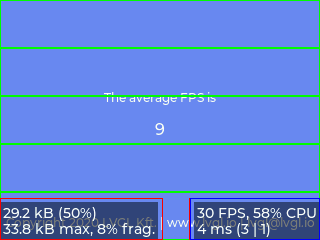
5分割 (30KB), 9FPS (16.6ms) 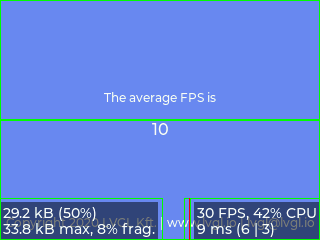
2分割 (75KB), 10FPS (16.1ms) - ダブルバッファ版(括弧内は画像メモリのサイズおよび1フレーム分の平均転送時間)
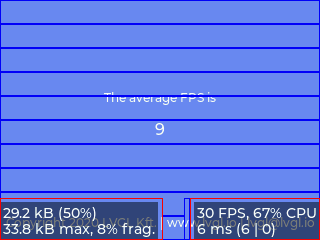
10分割 (30KB), 9FPS (16.2ms) 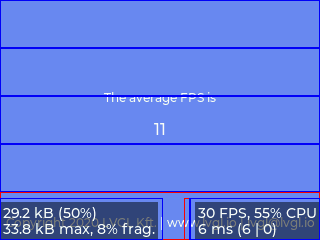
5分割 (60KB), 11FPS (15.9ms) 
3分割 (100KB), 12FPS (15.8ms)
それぞれの版を横に見ていくと、分割数が少なくなることで「パネルへの転送」を呼び出す回数が減り、関数コールのオーバーヘッドが小さくなってると考えられます。
また各版を縦で比べると、予想通りスループットが向上したことが分かります。特にパネル右下のパフォーマンス表示を見ると、見かけ上、「パネルへの転送」時間がほぼゼロに観測されていることが見て取れます。
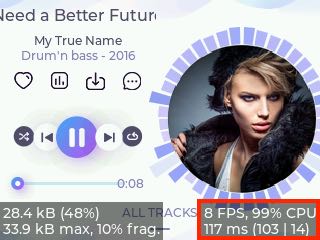
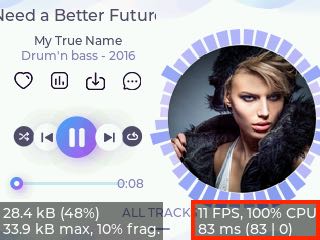
システムモニタの読み方
- メモリ(左下)
- 上段:
lv_conf.hで設定されたLV_MEM_SIZE中の使用量とその割合% - 下段:最大使用量と断片化の割合%
- 上段:
- パフォーマンス(右下)
- 上段:フレームレートの平均値と CPU 使用率
- 下段:1フレームの平均処理時間(レンダリング時間|パネルへの転送時間)
正直、体感上は微妙ですが、オリジナルの 8FPS が 最大で 12FPS に応答性が 1.5倍 上がったと考えれば、まぁ御の字でしょう 😉 次の動画では、1フレーム当たりの平均処理時間の最大値がおよそ 110msec → 80msec と、約 30msec 程度小さくなっています。
ただし3分割のダブルバッファ版は、ヒープの残りが約 84KB 1 になるので、アプリによってはキツイかもしれませんネ。
改めて、マジックナンバー 10 を考える
GPU のプログラミング経験が無いので推測になりますが、ハードウェアで並列化できるレンダリング数と省メモリが必要な安価な MCU とのバランスを考えれば、10 は絶妙な数値だと思います。逆に 10 だからこそ、辛うじて ESP32 でも動作が可能になっているとも言えます。
でも GPU に限らずハードウェアによるレンダリング機能を搭載した組み込み機器って、結構ハイエンドだと思うのですが、どうなんでしょう?
余談ですが、開発者さん曰く「クレイジーな機能を使わなければ、V9 を最小限に設定できます。角丸四角形、テキスト、画像の描画は依然として軽量です」とのことですが、LVGL V8 → V9 で LV_MEM_SIZE が 48MB から 64MB に増えました。
また この辺り の「パフォーマンス、優れた機能、省メモリのうち、優先すべき2つは?」的な議論とか、「V9.3 では MPU に力を入れるゾ」的な計画など、ますます多くのメモリが要求されるようになるのは確実だと思います 😮💨
まとめ
2回に渡り LVGL の応答性を上げる方法を探ってきました。まとめ直すと次の様になります。
- マジックナンバー
10は、1フレームにおけるレンダリング領域の分割数を表す - 分割数は、ハードウェアで並列化できるレンダリング領域の個数を想定している
- 分割数が小さくなるとオーバーヘッドは小さくなるが、画像メモリが大きくなる
- ダブルバッファ化とマルチコア/マルチタスク化でスループットを上げられる
- アプリ全体でメモリ容量の許す限り分割数を小さくすれば応答性を上げられる
また1フレームにかかる処理時間の短縮効果は、次の様に最大で 30mse 程度になりました。
- ダブルバッファ化+マルチコア/マルチタスク化で 15msec 前後
- 分割数の小さくすることで最大 15msec 程度
分割数については、GPU など特別なハードウェアを持たず全てをソフトウェアでレンダリングする ESP32 では、正直なところ
並列化の効果が限定的な ESP32 で、分割数 10 はチョット多過ぎ
と言うのが個人的な見解です。
とは言えダブルバッファ化も効果が薄く、マルチタスクなリアルタイムアプリ ─ 例えば以前に作った サーモグラフィカメラ もコア0にタスクを1個追加しているので、LVGL でさらに増えるとなるとタスク管理に苦労しそうです。
ということで、次は本丸の GUI デザインにチャレンジすべく、MP3 プレーヤーを仕込み中の今日この頃です 🌲🤧🌲
← ESP32 2432S028R (CYD)でLVGL - ダブルバッファとマルチコアで応答性を高める(1)
ESP32 2432S028R (CYD)でLVGL - I2SとInternal DACでMP3 Player - 基本動作編 →